In this Chapter
- Getting Started
- Working with Charactersets
- Available Charactersets
- Getting Help
Getting Started
Characterset support has long been a thorn in the side of many technical services librarians, because MARC data comes in so many different flavors and local character encodings. For catalogers in North America — two primary character encodings are dominant: MARC8 and UTF8. MARC8, of course, is an imaginary characterset that Libraries invented in the 1970s to enable extended Latinate characters to be represented. As additional characters were added, the MARC8 format was extended to provide access to Greek, Hebrew, CJK, etc. It evolved MARC8 into an escape-based character encoding, which means that it’s virtually useless and unreadable by anyone outside of the library.
Sadly, things don’t get much better if dealing with UTF8 data. In order to preserve round-trip ability with MARC8, most library specifications require the use of the KD notation around UTF8 data — a notation that separates characters from their diacritics, continuing the trend of making non-English language materials difficult to search and find.
MarcEdit provides for users a method to move data between various charactersets and character encodings. Character encodings (like UTF8 notation) is set in the MARCEngine Preferences, as noted: in Book 1: Chapter 3: Understanding the MarcEdit Preferences[ref]http://marcedit.reeset.net/learning_marcedit/welcome-to-marcedit/chapter-3-understanding-the-marcedit-preferences/3/[/ref]. For characterset conversions, users should utilize the Characterset Conversion tool found from within the MARC Tools window.
Working with Charactersets
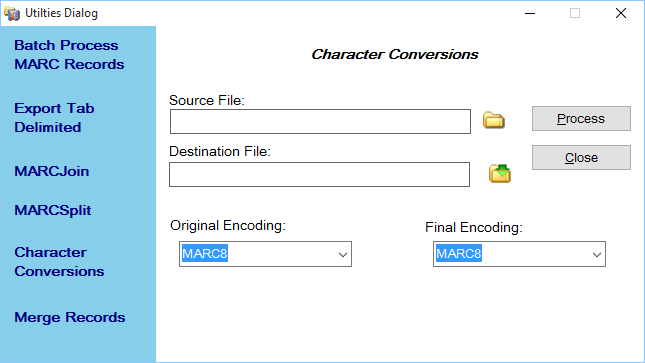
Figure 1: Characterset Conversions Window
The MarcEdit Characterset Conversions tool provides a batch method for changing data from one characterset to another. The program makes a couple of assumptions:
- That all the data in the file is in the same characterset
- That the user knows the original characterset encoding
[table] [attr style=”width:90px”], “MarcEdit do not have an automated tool for determining the characterset for your file. This is partly because at the binary level, many charactersets look the same. “[/table]
[attr style=”width:90px”], “MarcEdit do not have an automated tool for determining the characterset for your file. This is partly because at the binary level, many charactersets look the same. “[/table]
By default, MarcEdit’s Original Encoding and Final Encoding dropdown boxes are populated with the most common charactersets encountered by the MarcEdit user community.
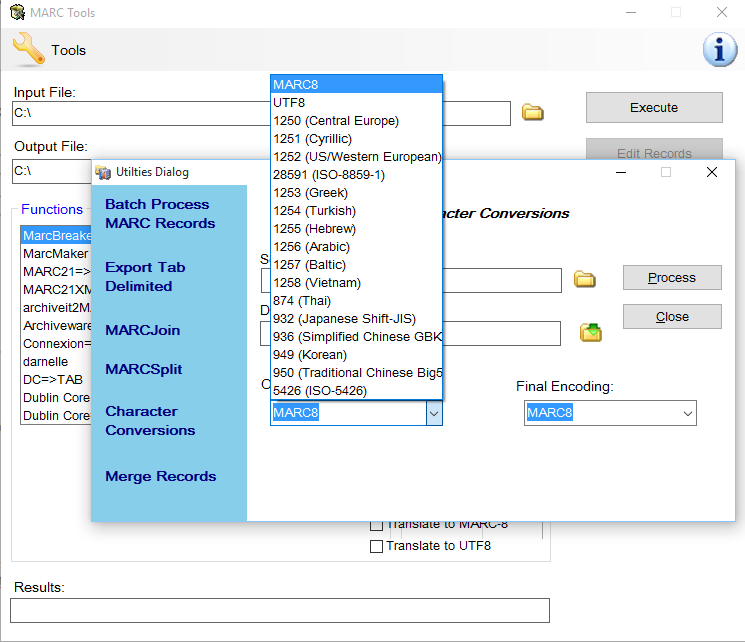
Figure 2: Available Charactersets
Charactersets are defined by the codepage (i.e., 1252) and then their human readable description. The codepage part is important — while this list represents the most common set of charactersets encountered by MarcEdit users, it is by no means an exhaustive list. Each operating system provides a set of supported charactersets…MarcEdit can utilize any characterset supported by the operating system so long as the codepage number is entered into the Original or Final encoding. For Windows users, Microsoft makes a list of supported codepages available in the Windows knowledge-base[ref]https://msdn.microsoft.com/en-us/library/dd317756(VS.85).aspx[/ref].
To use this function, follow these steps:
- Select the file to process and set it to the Source Text Box
- Set a save path in the Destination Text Box. This cannot be the same as the source file.
- Set the Original File Encoding. This is the encoding of the Source File.
- Set the Final Encoding. This is the encoding that the data should end up in
Important Notes
Switching between charactersets can be tricky, meaning that a handful of issues can cause hard to find problems.
- When converting to a characterset that is not UTF8 or MARC8, it is generally better to convert your data to UTF8 first, and then convert to the final encoding. You can go straight to your desired encoding, but if something goes wrong, its easier to debug the process.
- MarcEdit’s character conversion tool will not work if any structural errors exist in the record. Encoding changes require the evaluation of very precise sequences – if the file structure is incorrect, I can guarantee the conversion likely will be as well.
- Remember, MARC field length and record length is calculated by bytes, not characters. In MARC8, these two are the same thing. When dealing with UTF8 data, they are not. For records already approaching record or field limits — translating large amounts of diacritics to UTF8 could potentially cause structural errors (though this doesn’t happen often — and mostly occurs when moving data from XML into MARC).
Getting Help
So you have a data file and you want to encoding it into UTF8 but don’t know the original character encoding….that is a problem. Unfortunately, MarcEdit can’t automatically detect the file’s characterset. This is partly because many charactersets look identical at the binary level. However, I work with enough of them to maybe be able to give you some help.
- From Z39.50: Surprisingly, many Z39.50 servers return data in 28591 (ISO-8859-1) format (especially Innovative Interfaces Servers unless requested otherwise). This looks a lot like MARC8, but it isn’t. If you try processing data to UTF8 using MARC8 and the data isn’t correct, trying using this setting (or 1252 (US/Western European) — if the 28591 codepage doesn’t work).
- My codepage no longer is in use: This sometimes happens. If you look at the MarcEdit supported codepages, you’ll see one such codepage on this list: 5426 (ISO-5426). Codepage 5426[ref]http://www.iso.org/iso/iso_catalogue/catalogue_tc/catalogue_detail.htm?csnumber=11468[/ref] is an extension of the Latin alphabet used primary in minor European language and obsolete typography. However, there is a significant number of UNIMARC records in France that are stuck in this legacy format. To support the transition to UTF8, I added this to MarcEdit. So, if you run across a codepage that is no longer supported, let me know. There may be options.
Finally, the best place to get information about a files characterset encoding is to ask the individual or agency that provided you with the file. Good luck!