The Internet Archive does a lot of wonderful things — including, digitizing books for libraries. At Ohio State University, the Libraries worked with other CIC members to contribute ~a million items as part of the Google books projects, and ultimately, for inclusion into the HathiTrust. When this project wrapped up, we still wanted to include materials into the HathiTrust — but were looking for a way to maximize access to the materials (and simplify some of the digitization processing). Enter the Internet Archive. Like many other cultural heritage organizations, we provide them with content that they are hosting. You can see the collection here: https://archive.org/details/OhioStateUniversityLibrary.
One of the added benefits in working with the Internet Archive for Ohio State, is that a simple, well-documented, path exists for moving content between Internet Archive and the HathiTrust. Using their metadata specifications (https://www.hathitrust.org/bib_specifications),users can create MARCXML files that include the necessary information for HathiTrust to retrieve content, digitized into the Internet Archive.
To simplify this process at OSU, I’ve created a plugin for MarcEdit. This plugin is available in all versions of MarcEdit. This allows a user to point to a collection or contributor and a date range and generate a single MARCXML file that will facilitate the upload of that content into the HathiTrust. For information on downloading and managing plugins in MarcEdit, see: Managing Plugins in MarcEdit
The Plugin
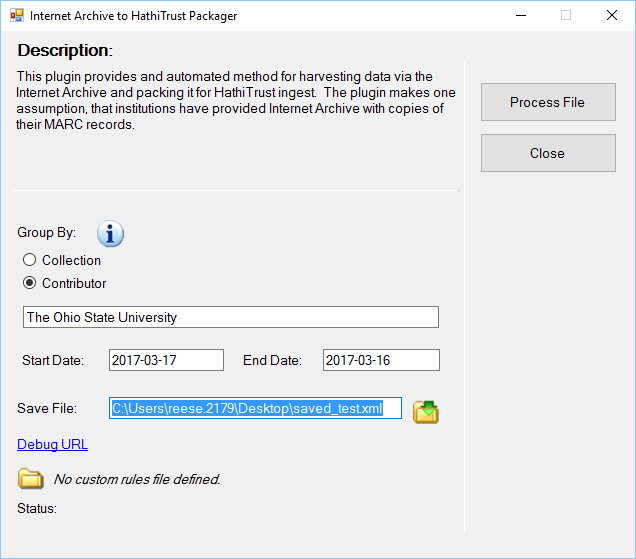
Internet Archive to HathiTrust Plugin
So what exactly does the tool do? Basically, the tool runs a query against the Internet Archive using either the Contributor information or Collection identifier. The tool then collects the identifiers of all the materials found between the noted dates, and extracts the MARC and the structural metadata at the Internet Archive. The tool then reads the data files, converting them to MARCXML and concatenating all records together into a single MARCXML file.
- Example file: https://1drv.ms/u/s!AvVB9SMVcU3Er5wM9jc9xBoxa57Ezw
**** Update ****
One change that was added recently is the ability to embed a custom rules file to aid in processing. This came up at Ohio State, and I figured it might be the case at other institutions as well. In our case, HathiTrust uses data found in our 925 field to capture enumeration (vol., issue, etc.), as well as the date of coverage. My understanding is that the date is used to help determine if the material can be publically available (public domain) or has limited availability. The problem with the data OSU was providing, is that the HathiTrust profile for our library assumes that the data that has the enumeration and the date live in the same subfield in the 925. However, at OSU, we keep this data in separate subfields. This was causing problems, as the date wasn’t being captured, so our content wasn’t always showing up as publically available. Since the 9xx fields are local data, I assumed that maybe this isn’t a problem that would show up just at OSUL — but since it’s local, fixing this isn’t something that can be easily coded for globally. So, I’ve enabled the ability to embed a rules file that will update the MARCXML utilizing XSLT (supports version 1-3 using Saxon 9.7.x as the engine). Here’s the example that I created that handles the OSUL case: https://github.com/reeset/ia2hathitrust/blob/master/ris_to_marc/example_rules_file.xsl. To utilize the rules file, the user just needs to create an XSLT file. I’d test it in a tool like Oxygen against a MARCXML file that you want to process, and then reference it here. And that’s it. The plugin will now use this data each time it harvests data from Internet Archive, applying the custom rules file and augmenting the metadata to suite your needs.
*** End update ***
At this point, I’m looking for a couple folks that use the Internet Archive, contribute (or would like to contribute) to the HathiTrust, and use MarcEdit — that might be able to put this through it’s paces. We know that it works here at OSU — I’d like to validate that these assumptions work more broadly.
For those interested in the source code — it will be available in my github repo as soon as I get a chance to package it.
Troubleshooting
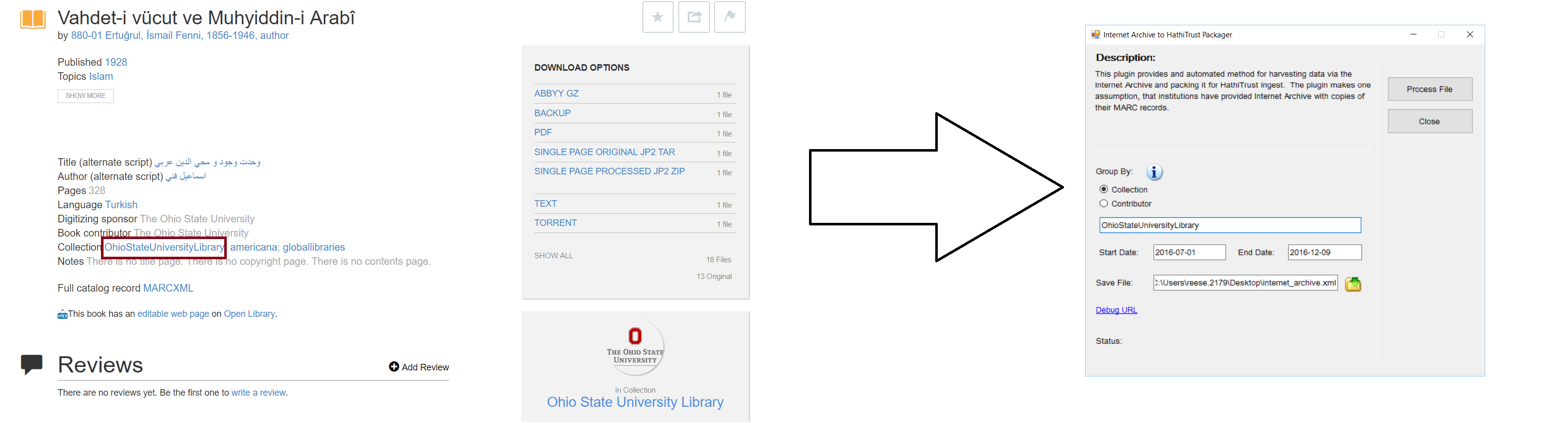
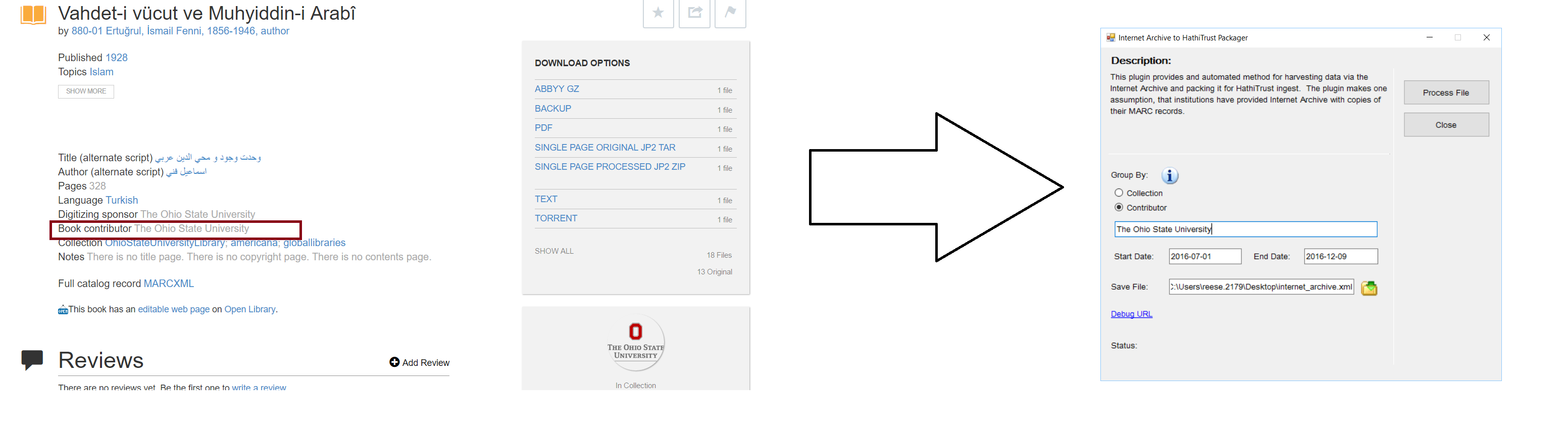
Probably the most difficult part of the process is figuring out what data the plugin needs to Group the data. MarcEdit provides two options for grouping data: by collection or by contributor. This information is easily found on any book display page in the Internet Archive.
By Contributor:
By Collection: